字节对MoE模型训练成本再“砍一刀”,大幅降低成本。
3月10日,字节豆包大模型团队官宣开源一项针对MoE架构的关键优化技术,可将大模型训练效率提升1.7倍,成本节省40%。据悉,该技术已实际应用于字节的万卡集群训练,累计帮助节省了数百万GPU小时训练算力。
早前,豆包团队发布了新一代稀疏架构UltraMem,将模型推理成本砍掉83%,此次,又开源了COMET,向模型训练成本出手。从技术理念上看,两者还可以结合使用,组成一套“砍价刀法”。
据悉,MoE是当前大模型的主流架构,但其在分布式训练中存在大量跨设备通信开销,严重制约了大模型训练效率和成本。以海外主流模型Mixtral-8x7B为例,其训练过程中通信时间占比可高达40%。针对这一难题,字节在内部研发了COMET计算-通信重叠技术,通过多项创新,大幅压缩了MoE专家通信空转时间。
相较DeepSeek近期开源的DualPipe等MoE优化方案,COMET可以像插件一样直接接入已有的MoE训练框架,支持业界绝大部分主流大模型,无需对训练框架进行侵入式改动。因简洁、通用的设计理念,该工作以5/5/5/4的高分入选全球机器学习系统顶级会议MLSys2025,被认为“在大规模生产环境中极具应用潜力”。
具体而言,COMET从系统层面建立了面向MoE的细粒度流水线编程方式,通过引入共享张量依赖解析、自适应负载分配两项关键机制,来解决通信与计算之间的粒度错配问题,并精准平衡通信与计算负载,最终大幅提升MoE流水线整体效率。引入COMET后,单个MoE层上可实现1.96倍加速、端到端平均1.71倍效率提升,且在不同并行策略、输入规模及硬件环境下均表现稳定。
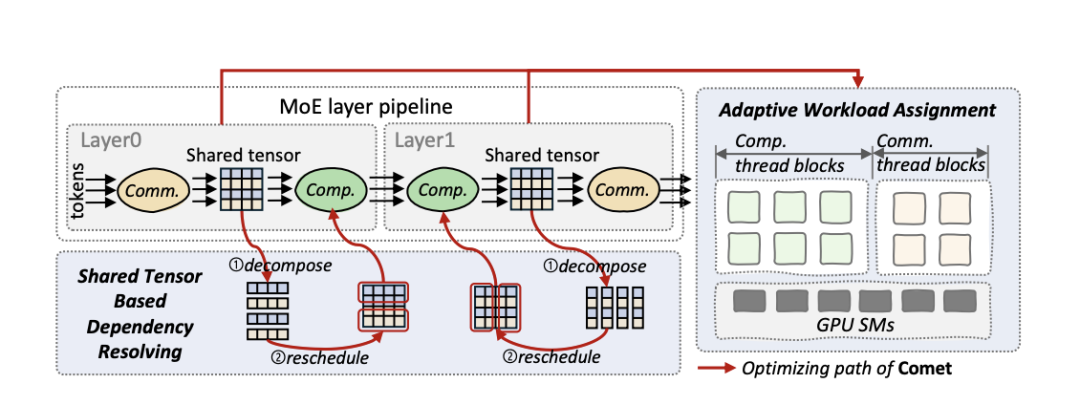
COMET的设计结构
值得一提的是,COMET与DeepSeek研发的DualPipe方案还可以联合使用。在降低MoE通信开销上,COMET采用了计算-通信融合算子的优化方式,DualPipe则通过排布算子来掩盖通信,两种方案并不冲突,结合使用或将更大幅度压缩模型训练成本。
目前,COMET支持多种MoE并行模式,部署灵活、方便。同时,COMET核心代码已开源,并向开发者提供了一套友好的PythonAPI,计划兼容Triton等编译生态。
文/广州日报新花城大象影视:邓莉
图:字节跳动提供
广州日报新花城编辑:麦晓颖